Желим вам пуно успеха у раду у 2013. години и да технологија ради за вас!
Док трају празници и док се одмарате од обавеза, погледајте и неке од занимљивих ресурса који су вам на располагању. Неки су бесплатни, а други се наплаћују.
Да ли сте чули за "лингви"? Изузетан сајт који омогућава претрагу термина у контексту. Највише користи онима који преводе у језичким паровима великих европских језика: енглеском, немачком, шпанском, француском и португалском. Реч или фразу коју унесете у поље за претрагу, систем претражује у корпусу већ преведених докумената у комбинацији са речницима датог језичког пара.
Ако радите са документима у ПДФ формату, од помоћи за обраду текста и његову припрему за превођење у неком од алата преводилачког окружења након препознавања истог у алату за OCR (ен. Optical Character Recognition), може вам помоћи CodeZapper. Овај програм је направио Дејв Тарнер, а представља један од обавезних алата у арсеналу стручних преводилаца широм света. За преузимање истог, потребно је издвојити 20 евра.
С друге стране, један од многих бесплатних алата за конвертовање ваших докумената у ПДФ можете преузети овде. За коришћење бесплатне верзије морате истрпети пар реклама сваки пут када правите ПДФ документ. У супротном, постоји и опција која се плаћа и рекламе су прошлост.
Ако никада раније нисте користили неки од преводилачких алата, не знате шта су или се бринете у који од њих да инвестирате, пробајте са бесплатним алатом Омега Т. Сада више нема изговора.
По завршетку рада на преводу, када је потребно извршити финалну контролу и уверити се да је посао ваљано урађен, на располагању су вам интегрисани или одвојени програми за осигурање квалитета. Један од најбољих јесте програм компаније ApSIC - Xbench. Недавно је решила да почне да наплаћује за свој софтвер и објавила је верзију бета, а на новом сајту компаније можете прочитати више о плановима. Верзија ApSIC Xbench 2.9 је и даље бесплатна и то ће и остати, док се верзија 3.0 плаћа.
Још један од софтвера за осигурање квалитета је и бесплатни алат CheckMate. Лично сам задовољан интегрисаним модулом за осигурање квалитета у програму memoQ који највише користим, али свакако - ови специјализовани алати садрже и неке додатне опције.
Надам се да је бар нека од горе наведених алатки нова за вас и да ће вам помоћи у раду у Новој години, на лично и на задовољство ваших клијената.
Још једном вам желим срећне Новогодишње и Божићне празнике и успех у 2013. години!
понедељак, 31. децембар 2012.
среда, 26. децембар 2012.
Језички терминал
У свом обраћању корисницима софтвера компаније Kilgray (текст целог блога можете прочитати на енглеском овде), Иштван Ленђел (István Lengyel) је, између осталих новости које се тичу своје компаније најавио и једну нову услугу за преводиоце и остале лингвисте: језички терминал!

Компанија је после дуго времена и заобилажења тренда у коришћењу тзв. технологије "облака" (стављање одређених хардверских и софтверских ресурса на располагање кориснику путем мреже - најчешће преко интернета), одлучила да понуди бесплатну, односно услугу чија је цена у разумним границама, преводиоцима, агенцијама и корпоративним корисницима.
Довољно је регистровати се на порталу и одмах можете да користите 1024 мегабајта слободног простора за складиштење својих пројеката (одрађених у програму memoQ) и ресурса, којима затим можете приступити са било ког рачунара повезаног на интернет.
Додатна опција, коју сам одмах и у пракси искористио јесте могућност конвертовања .indd, .idml и .inx фајлова (извезених из програма InDesign) у .xliff фајлове који омогућавају контекстуални приказ текста (онаквог какав је припремљен за штампу) и креирање ПДФ документа истог који такође можете користити као референцу.
Када сте завршили са преводом, фајл можете поново конвертовати у изворни формат преко овог портала.
Будући да смо ми Срби небески народ, рад у облаку не би требало да нам представља већи проблем.

Компанија је после дуго времена и заобилажења тренда у коришћењу тзв. технологије "облака" (стављање одређених хардверских и софтверских ресурса на располагање кориснику путем мреже - најчешће преко интернета), одлучила да понуди бесплатну, односно услугу чија је цена у разумним границама, преводиоцима, агенцијама и корпоративним корисницима.
Довољно је регистровати се на порталу и одмах можете да користите 1024 мегабајта слободног простора за складиштење својих пројеката (одрађених у програму memoQ) и ресурса, којима затим можете приступити са било ког рачунара повезаног на интернет.
Додатна опција, коју сам одмах и у пракси искористио јесте могућност конвертовања .indd, .idml и .inx фајлова (извезених из програма InDesign) у .xliff фајлове који омогућавају контекстуални приказ текста (онаквог какав је припремљен за штампу) и креирање ПДФ документа истог који такође можете користити као референцу.
Када сте завршили са преводом, фајл можете поново конвертовати у изворни формат преко овог портала.
Будући да смо ми Срби небески народ, рад у облаку не би требало да нам представља већи проблем.
субота, 22. децембар 2012.
Са регуларним изразима - стање редовно
Иако ова тема донекле задире у "тамну страну" и више је својствена програмерима, може да користи свима који се сусрећу у свом преводилачком раду са текстом који садржи већи број тзв. регуларних израза (енг. regular expressions, regexp, regex). Овај чланак је наставак претходног о раду на сложеним пројектима.
Пре него што пређемо на конкретне примере употребе регуларних израза, даћу вам неколико примера ситуација у којима знање писања истих може да вам донесе велику уштеду времена и да умањи ризик од грешке.
- шифре производа (у брошурама одређене компаније, нпр. АБ123Ц3, АЦ234У8, ДД889А1...),
- бројеви телефона, факса (00381 11 555 6667, итд, где постоји утврђени формат)
- интернет адресе
- имејл адресе
- итд.
У прошлом примеру смо урадили следеће: направили смо виртуелни документ састављен од свих мањих докумената у пројекту - при чему смо већ преведене сегменте закључали и у опцији Create view (Креирај приказ) одабрали опцију једноставног спајања докумената, али без закључаних сегмената.

Када је приказ креиран, отворићемо га као и било који други документ. Будући да смо већ у претходном чланку видели да документи садрже велики број шифара производа, следећи корак је да исте претворимо у тагове.
Из траке са алатима одаберите опцију Format (Формат), а у оквиру ње опцију Run Regex Tagger... (Покрени конвертор регуларних израза у тагове...).

Појављује се следећи прозор:

У поље Regular expression (на слици уоквирено црвеном бојом), уносимо формулу према којој ће сви изрази који задовољавају задате вредности бити претворени у тагове. У нашем случају, желимо да конвертујемо све шифре производа који прате следећи шаблон: 6 бројева, 3 словна места, 1 број, као у примеру са слике у наставку (083891COM5, 088111COM5, 083772COM5, итд.):

Формула ће изгледати овако:
\d{6}[A-Za-z]{3}\d
при чему је значење сваког од елемената формуле следеће:
\d - број (0-9)
{num} - број понављања ставке која претходи ИЛИ опсег (нпр. {3} значи 3 цифре, док {2,4} значи 2, 3 или 4 цифре)
[A-Za-z] - било које слово (велико или мало)

Када сте унели формулу у горе означено поље, кликните на дугме Add (Додај). Правило (тј. формула) ће се појавити у пољу Rules (Правила). У пољу Results (Резултати), црвеном бојом су обележени сви регуларни изрази које ће унесена формула претворити у тагове. У случају да нисте задовољни резултатом (догађа се да нисте добро унели формулу или сте превидели неку вредност), већ унесену формулу можете кориговати у пољу Regular expression и притиснути на дугме Change (Измени). Ако се међу правилима налази више формула, одаберите ону коју желите да измените, па тек онда вршите измене.
Ако сте задовољни резултатом, дата правила можете снимити кликом на зелени крстић у горњем десном углу (отвориће се прозор за конфигурацију филтера - унесите назив који ће вас асоцирати на формуле за будућу употребу) и притисните дугме у доњем углу прозора - Run tagger now.

Промене у прозору за превођење су следеће:

Додатни разлог за конвертовање регуларних израза је и тај што проценат поклапања са резултатима из преводилачке меморије може бити много већи него у случају да је израз остао неконвертован у таг. На пример, ако сте раније превели nozzle у сегменту у коме није било тагова, memoQ ће вам у нашем сегменту (сегмент 28. на слици) предложити решење чији ће проценат поклапања бити преко 90% (вероватно од 97% до 99%). Да је израз остао неконвертован, проценат поклапања би био испод 50% или отприлике у том делу спектра поклапања јер би memoQ на сам израз гледао као на једну реч и десет карактера (самим тим, не би ни понудио решење из меморије ако сте у подешавањима подесили доњи праг на 70% и сл.).
Имејл адресе
Ако више не желите да имате посла са имејл адресама у било ком формату оне биле, онда унесите следећу формулу у конвертор регуларних израза:
\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,4}\b
У овом примеру, учитао сам могуће (али и погрешне) имејл адресе на различитим доменима (укључујући и погрешне домене са доњом цртицом "_"), учитао их у програм и написао горњу формулу. Погледајте примере адреса:

Дакле, свака имејл адреса има следећи шаблон: одређени број карактера (словних или бројчаних вредности, симбола, итд.) између којих нема размака, симбол "@", одређени број карактера, тачку и од два до четири словна места (нпр. .rs, .com, .info, .uk.com).
Погледајмо још једном горњу формулу, овога пута разложену на сваку од категорија наведених у претходном пасусу:
\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,4}\b
\b - овај метакарактер се користи за претрагу само целих низова. То значи да се john из (погрешне адресе) john doe@john-doe.com, неће сматрати делом низа јер је одвојен размаком.
Низ који се налази између угластих заграда говори да се на датом месту могу наћи сва велика и мала слова, бројеви од 0 до 9, као и знакови: тачка, доња црта, знак за проценат, плус и цртица.
Тачка означава било који карактер (слово, број, симбол), али ако се испред тачке стави коса црта "\", онда то једноставно значи тачку. Дата коса црта (енг. "escape" character, modifier) заправо означава да је знак који следи само тај знак и ништа више (изузеци су број (\d), размак (\s), цела реч (\w или \b)). На пример, "\/" значи "/", "\@" значи "@", "\+" значи "+", итд.
Остатак формуле би требало да буде јасан.
А сада да видимо резултате горње формуле на делу:

Програм је правилно протумачио правило и претворио исправне имејл адресе у тагове, док је у случају неисправних адреса извршио претварање у таг само исправног дела или је прескочио целокупан низ.
На мрежи постоји велики број сајтова посвећених регуларним изразима, ако баш желите да се упуштате у целокупну проблематику. За почетак, довољно је да се упознате са основама. Неке од најчешће коришћених метакарактера, као и њихово значење, објављујем у следећем чланку.
Пре него што пређемо на конкретне примере употребе регуларних израза, даћу вам неколико примера ситуација у којима знање писања истих може да вам донесе велику уштеду времена и да умањи ризик од грешке.
- шифре производа (у брошурама одређене компаније, нпр. АБ123Ц3, АЦ234У8, ДД889А1...),
- бројеви телефона, факса (00381 11 555 6667, итд, где постоји утврђени формат)
- интернет адресе
- имејл адресе
- итд.
У прошлом примеру смо урадили следеће: направили смо виртуелни документ састављен од свих мањих докумената у пројекту - при чему смо већ преведене сегменте закључали и у опцији Create view (Креирај приказ) одабрали опцију једноставног спајања докумената, али без закључаних сегмената.
Када је приказ креиран, отворићемо га као и било који други документ. Будући да смо већ у претходном чланку видели да документи садрже велики број шифара производа, следећи корак је да исте претворимо у тагове.
Из траке са алатима одаберите опцију Format (Формат), а у оквиру ње опцију Run Regex Tagger... (Покрени конвертор регуларних израза у тагове...).

Појављује се следећи прозор:

У поље Regular expression (на слици уоквирено црвеном бојом), уносимо формулу према којој ће сви изрази који задовољавају задате вредности бити претворени у тагове. У нашем случају, желимо да конвертујемо све шифре производа који прате следећи шаблон: 6 бројева, 3 словна места, 1 број, као у примеру са слике у наставку (083891COM5, 088111COM5, 083772COM5, итд.):

Формула ће изгледати овако:
\d{6}[A-Za-z]{3}\d
при чему је значење сваког од елемената формуле следеће:
\d - број (0-9)
{num} - број понављања ставке која претходи ИЛИ опсег (нпр. {3} значи 3 цифре, док {2,4} значи 2, 3 или 4 цифре)
[A-Za-z] - било које слово (велико или мало)

Када сте унели формулу у горе означено поље, кликните на дугме Add (Додај). Правило (тј. формула) ће се појавити у пољу Rules (Правила). У пољу Results (Резултати), црвеном бојом су обележени сви регуларни изрази које ће унесена формула претворити у тагове. У случају да нисте задовољни резултатом (догађа се да нисте добро унели формулу или сте превидели неку вредност), већ унесену формулу можете кориговати у пољу Regular expression и притиснути на дугме Change (Измени). Ако се међу правилима налази више формула, одаберите ону коју желите да измените, па тек онда вршите измене.
Ако сте задовољни резултатом, дата правила можете снимити кликом на зелени крстић у горњем десном углу (отвориће се прозор за конфигурацију филтера - унесите назив који ће вас асоцирати на формуле за будућу употребу) и притисните дугме у доњем углу прозора - Run tagger now.

Промене у прозору за превођење су следеће:

Додатни разлог за конвертовање регуларних израза је и тај што проценат поклапања са резултатима из преводилачке меморије може бити много већи него у случају да је израз остао неконвертован у таг. На пример, ако сте раније превели nozzle у сегменту у коме није било тагова, memoQ ће вам у нашем сегменту (сегмент 28. на слици) предложити решење чији ће проценат поклапања бити преко 90% (вероватно од 97% до 99%). Да је израз остао неконвертован, проценат поклапања би био испод 50% или отприлике у том делу спектра поклапања јер би memoQ на сам израз гледао као на једну реч и десет карактера (самим тим, не би ни понудио решење из меморије ако сте у подешавањима подесили доњи праг на 70% и сл.).
Имејл адресе
Ако више не желите да имате посла са имејл адресама у било ком формату оне биле, онда унесите следећу формулу у конвертор регуларних израза:
\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,4}\b
У овом примеру, учитао сам могуће (али и погрешне) имејл адресе на различитим доменима (укључујући и погрешне домене са доњом цртицом "_"), учитао их у програм и написао горњу формулу. Погледајте примере адреса:

Дакле, свака имејл адреса има следећи шаблон: одређени број карактера (словних или бројчаних вредности, симбола, итд.) између којих нема размака, симбол "@", одређени број карактера, тачку и од два до четири словна места (нпр. .rs, .com, .info, .uk.com).
Погледајмо још једном горњу формулу, овога пута разложену на сваку од категорија наведених у претходном пасусу:
\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,4}\b
\b - овај метакарактер се користи за претрагу само целих низова. То значи да се john из (погрешне адресе) john doe@john-doe.com, неће сматрати делом низа јер је одвојен размаком.
Низ који се налази између угластих заграда говори да се на датом месту могу наћи сва велика и мала слова, бројеви од 0 до 9, као и знакови: тачка, доња црта, знак за проценат, плус и цртица.
Тачка означава било који карактер (слово, број, симбол), али ако се испред тачке стави коса црта "\", онда то једноставно значи тачку. Дата коса црта (енг. "escape" character, modifier) заправо означава да је знак који следи само тај знак и ништа више (изузеци су број (\d), размак (\s), цела реч (\w или \b)). На пример, "\/" значи "/", "\@" значи "@", "\+" значи "+", итд.
Остатак формуле би требало да буде јасан.
А сада да видимо резултате горње формуле на делу:

Програм је правилно протумачио правило и претворио исправне имејл адресе у тагове, док је у случају неисправних адреса извршио претварање у таг само исправног дела или је прескочио целокупан низ.
На мрежи постоји велики број сајтова посвећених регуларним изразима, ако баш желите да се упуштате у целокупну проблематику. За почетак, довољно је да се упознате са основама. Неке од најчешће коришћених метакарактера, као и њихово значење, објављујем у следећем чланку.
среда, 19. децембар 2012.
Рад на сложеним пројектима
Прво питање које себи можете поставити овом приликом јесте - "Шта су то сложени пројекти?" Дефиниција сложеног је опширна и сигурно има различита значења за различите лингвисте.
То могу бити:
- велики обим текста
- егзотични формати изворних докумената
- велики број изворних докумената
- већи број лингвиста (преводилаца, лектора, редактора) који раде на документу - евентуално истовремено (у случају рада преко сервера)
- рад у различитим окружењима за превођење (сваки од лингвиста користи другачији програм за рад - од једноставног Word-а, преко различитих алата CAT који постоје на тржишту, нпр. memoQ, SDL Trados, Déjà Vu, итд.)
- посебни делови документа које треба превести (а друге делове изоставити)
- све ово наведено заједно
Овом приликом ћемо се сконцентрисати на пример рада на документима који испуњавају следеће услове: велики број докумената, велики обим текста, лингвиста ради у преводилачком окружењу (memoQ) које је другачије од оног у коме је клијент припремио документе за рад (Trados), а у цео посао су укључени и други лингвисти који раде у истом или другачијем окружењу (memoQ, Trados, Word).
Алат који користим у раду и који највише одговара мојим (не малим) потребама и преференцијама је memoQ. Са једним великим клијентом сам раније, кад сам знао мање, направио једну кључну грешку у обради документа која ме је коштала значајног умањења од око 200 евра - на које сам пристао, иако смо се и ја и клијент намучили око документа и изгубили и време и живце. Радило се о томе да је клијент користио, а и даље у свом раду користи Trados (захтевали су да радим на њиховом серверу, такође користећи Trados).
Будући да ми рад са Традосом, поготову са верзијом 7 није одговарао због немогућности коришћења различитих филтера и опција закључавања сегмената, као и слаб увид у "велику слику", одлучио сам да документе које сам добио у .ttx формату директно учитам у memoQ, преведем и пошаљем клијенту. ГРЕШКА! Документе је прво потребно припремити за рад у другом програму. Ево како:
У Translator's Workbench, одаберите опцију Options -> Translation Memory Options... (Опције за преводилачку меморију):






Погледајмо за тренутак исти овај документ у Trados TagEditor-у. Поставиио сам курсор испред броја 22000198 и притиснуо комбинацију тастера Alt+Home, да бих отворио сегмент за превођење. Trados TagEditor је прескочио све бројеве који стоје самостално (ово је разлика у односу на memoQ који учитава и све бројеве у документу) и отворио први следећи сегмент који садржи бар једно слово.

Овај претходни екран сам вам приказао да бисте знали зашто ћемо приликом учитавања у memoQ морати да штиклирамо опцију Import unsegmented content (Увези несегментирани садржај). Тај несегментирани садржај су управо бројеви. Ово је важно јер у супротном може доћи до некомпатибилне верзије документа након извоза (експортовања) документа обрађеног у програму memoQ или било ком другом програму.
Када учитате своје документе у memoQ, програм ће аутоматски препознати да је реч о .ttx филтеру и појавиће се следећи прозор (видите да су сви документи учитани и да поред њих стоји зелени штиклирани знак - дакле, memoQ је препознао тип фајла).

Међутим, у овом случају, мораћемо да променимо филтер и конфигурацију (кликните на опцију у доњем левом углу означену бројем 1 и уоквирену (Change filter and configuration for all). Појавиће се прозор који је у првом плану на слици: штиклирајте опцију Import unsegmented content (то је оно што смо раније поменули):

Сачувајте овај филтер (са подешавањима која сте одабрали претходно) за будуће сличне ситуације тако што ћете кликнути на зелени знак плус. Ја сам га назвао TagEditor Presegmented да би ме подсетило да је реч о документима чија је припрема одрађена у TagEditor-у.

Сада су документи учитани и можете почети да радите на преводу. Оно што ћете приметити када отворите један од тих докумената је следеће:

Неки сегменти ће бити преведени (означени плавом бојом и процентом тачности од 100%). То је зато што смо током пре-сегметнације користили преводилачку меморију клијента која је већ садржала одређене преводе. Видите да је у случају бројева циљно поље празно (зато што Традос не сегментира бројеве) али су они свеједно учитани (јер смо одабрали опцију за увоз несегментираног садржаја). У осталим случајевима, у пољу за превод текст је исти као у изворном тексту.
Уколико извршимо анализу докумената, видећемо следеће резултате:

Исти ти резултати, само графички обрађени (из дела Project Home -> Settings -> Analysis -> Create report):

Оно што ћемо сада урадити јесте да потврдимо све сегменте који су 100% тачни (на основу меморије клијента). Идите на опцију Operations (Операције) и одаберите Confirm and Update Rows... (Потврди и ажурирај редове):




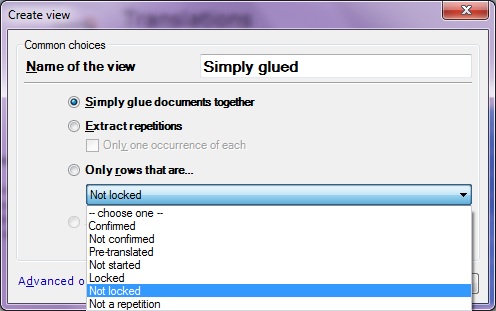
Следећи корак (ово није нужан корак, али помаже значајно у случају да има много докумената и да се одређени садржаји у сваком од њих понављају) јесте да креирамо један виртуелни документ који ће садржати све сегменте из свих ових докумената. То се ради тако што ћете у доњем десном углу програма memoQ кликнути на опцију Create view (Креирај приказ). Појављује се следећи прозор:

Име приказа одредите сами. У овај приказ желим да укључим само оне редове, тј. сегменте који нису потврђени. Одаберите одговарајућу опцију као што је приказано на слици горе. Кликните на ОК.
На картици Views појављује се документ под горе наведеним именом. Отворите га и погледајте како изгледа.
Врло брзо, увиђате да у документу има доста шифара производа које следе одређени шаблон - низ бројева, словне вредности, низ бројева.
Да не бисте губили време и ризиковали да погрешно унесете шифру у превод, постоји једна изузетно корисна, иако врло компликована опција - таговања, односно, закључавања одређеног текста који се појављује у документу и који следи одређени шаблон. Опција за то је Regex Tagger, при чему Regex значи Regular Expressions.
Али о томе следећи пут.
То могу бити:
- велики обим текста
- егзотични формати изворних докумената
- велики број изворних докумената
- већи број лингвиста (преводилаца, лектора, редактора) који раде на документу - евентуално истовремено (у случају рада преко сервера)
- рад у различитим окружењима за превођење (сваки од лингвиста користи другачији програм за рад - од једноставног Word-а, преко различитих алата CAT који постоје на тржишту, нпр. memoQ, SDL Trados, Déjà Vu, итд.)
- посебни делови документа које треба превести (а друге делове изоставити)
- све ово наведено заједно
Овом приликом ћемо се сконцентрисати на пример рада на документима који испуњавају следеће услове: велики број докумената, велики обим текста, лингвиста ради у преводилачком окружењу (memoQ) које је другачије од оног у коме је клијент припремио документе за рад (Trados), а у цео посао су укључени и други лингвисти који раде у истом или другачијем окружењу (memoQ, Trados, Word).
Алат који користим у раду и који највише одговара мојим (не малим) потребама и преференцијама је memoQ. Са једним великим клијентом сам раније, кад сам знао мање, направио једну кључну грешку у обради документа која ме је коштала значајног умањења од око 200 евра - на које сам пристао, иако смо се и ја и клијент намучили око документа и изгубили и време и живце. Радило се о томе да је клијент користио, а и даље у свом раду користи Trados (захтевали су да радим на њиховом серверу, такође користећи Trados).
Будући да ми рад са Традосом, поготову са верзијом 7 није одговарао због немогућности коришћења различитих филтера и опција закључавања сегмената, као и слаб увид у "велику слику", одлучио сам да документе које сам добио у .ttx формату директно учитам у memoQ, преведем и пошаљем клијенту. ГРЕШКА! Документе је прво потребно припремити за рад у другом програму. Ево како:
У Translator's Workbench, одаберите опцију Options -> Translation Memory Options... (Опције за преводилачку меморију):

На картици General (Опште), штиклирајте поље Copy source on no match (Копирај изворни текст у поље за циљни текст у случају да у преводилачкој меморији већ не постоји одговарајуће решење - тј. да сегмент већ није преведен). Кликните на ОК.

Затим, одаберите опцију Tools (Алати) и у оквиру ње опцију Translate (Преведи). Ово се још зове пре-сегментација (pre-segmenting), односно припрема сегмената изворног текста за накнадну обраду.
Штиклирајте поље Segment unknown sentences (Изврши сегментирање непознатих реченица) и означите опцију Update document (Ажурирај документ). Затим кликните на дугме Add (Додај) у горњем левом углу и одаберите документ који желите да припремите са одговарајуће локације на вашем рачунару.
Дозволите програму да изврши обраду.
Пошто је реч о сложеним пројектима, закомпликоваћемо ствари додатно учитавањем још фајлова (да бисмо добили на броју докумената и обиму текста). Поновићемо кораке након додавања документа. Можете одабрати више докумената истовремено.
Погледајмо за тренутак исти овај документ у Trados TagEditor-у. Поставиио сам курсор испред броја 22000198 и притиснуо комбинацију тастера Alt+Home, да бих отворио сегмент за превођење. Trados TagEditor је прескочио све бројеве који стоје самостално (ово је разлика у односу на memoQ који учитава и све бројеве у документу) и отворио први следећи сегмент који садржи бар једно слово.

Овај претходни екран сам вам приказао да бисте знали зашто ћемо приликом учитавања у memoQ морати да штиклирамо опцију Import unsegmented content (Увези несегментирани садржај). Тај несегментирани садржај су управо бројеви. Ово је важно јер у супротном може доћи до некомпатибилне верзије документа након извоза (експортовања) документа обрађеног у програму memoQ или било ком другом програму.
Када учитате своје документе у memoQ, програм ће аутоматски препознати да је реч о .ttx филтеру и појавиће се следећи прозор (видите да су сви документи учитани и да поред њих стоји зелени штиклирани знак - дакле, memoQ је препознао тип фајла).
Међутим, у овом случају, мораћемо да променимо филтер и конфигурацију (кликните на опцију у доњем левом углу означену бројем 1 и уоквирену (Change filter and configuration for all). Појавиће се прозор који је у првом плану на слици: штиклирајте опцију Import unsegmented content (то је оно што смо раније поменули):
Сачувајте овај филтер (са подешавањима која сте одабрали претходно) за будуће сличне ситуације тако што ћете кликнути на зелени знак плус. Ја сам га назвао TagEditor Presegmented да би ме подсетило да је реч о документима чија је припрема одрађена у TagEditor-у.

Сада су документи учитани и можете почети да радите на преводу. Оно што ћете приметити када отворите један од тих докумената је следеће:
Неки сегменти ће бити преведени (означени плавом бојом и процентом тачности од 100%). То је зато што смо током пре-сегметнације користили преводилачку меморију клијента која је већ садржала одређене преводе. Видите да је у случају бројева циљно поље празно (зато што Традос не сегментира бројеве) али су они свеједно учитани (јер смо одабрали опцију за увоз несегментираног садржаја). У осталим случајевима, у пољу за превод текст је исти као у изворном тексту.
Уколико извршимо анализу докумената, видећемо следеће резултате:

Исти ти резултати, само графички обрађени (из дела Project Home -> Settings -> Analysis -> Create report):

Оно што ћемо сада урадити јесте да потврдимо све сегменте који су 100% тачни (на основу меморије клијента). Идите на опцију Operations (Операције) и одаберите Confirm and Update Rows... (Потврди и ажурирај редове):

Штиклирајте само кућицу 100% or 101% pre-translated (100% или 101% претходно преведени):

Када кликнете на ОК, појављује се следећи прозор - извештај. Кликните на Close (Затвори).

Видећете да је проценат завршености одређених докумената промењен:

Следећи корак (ово није нужан корак, али помаже значајно у случају да има много докумената и да се одређени садржаји у сваком од њих понављају) јесте да креирамо један виртуелни документ који ће садржати све сегменте из свих ових докумената. То се ради тако што ћете у доњем десном углу програма memoQ кликнути на опцију Create view (Креирај приказ). Појављује се следећи прозор:

Име приказа одредите сами. У овај приказ желим да укључим само оне редове, тј. сегменте који нису потврђени. Одаберите одговарајућу опцију као што је приказано на слици горе. Кликните на ОК.
На картици Views појављује се документ под горе наведеним именом. Отворите га и погледајте како изгледа.
Врло брзо, увиђате да у документу има доста шифара производа које следе одређени шаблон - низ бројева, словне вредности, низ бројева.
Да не бисте губили време и ризиковали да погрешно унесете шифру у превод, постоји једна изузетно корисна, иако врло компликована опција - таговања, односно, закључавања одређеног текста који се појављује у документу и који следи одређени шаблон. Опција за то је Regex Tagger, при чему Regex значи Regular Expressions.
понедељак, 17. децембар 2012.
Кад не иде, онда не иде...
Урбана легенда каже да се Шевролетов чувени модел "Нова" слабо продавао у Мексику и другим латиноамеричким државама управо због назива "Нова". Разлог је тај што "no va" на шпанском значи "не иде".
Истина је да се овај модел ипак одлично продавао у Латинској Америци, али прича као таква је школски пример за часове маркетинга и именовање нових производа.
Посао провере имена бренда који се жели пласирати на одређено тржиште од лингвисте захтева управо то - да истражи да ли нека реч или име производа могу имати било какве негативне асоцијације на језику крајњег корисника.
Потребно је размислити о следећем:
- како реч изгледа на "папиру"
- како звучи или како може да звучи
Могући проблеми
Српски не познаје удвајање слова (осим у случају суперлатива где се "ј" може наћи поред другог "ј"). Ако име бренда садржи дупло слово, нпр. Gloopost, а клијент од вас тражи да му кажете како ће говорници матерњег језика (српског) изговорити име овог бренда, шта ћете му рећи?
Јасно је. Глупост. Али...
Да ли би и ваша баба ово изговорила тако? Можда, али тек у другом покушају јер би јој се учинило да личи на прво изговорено "глопост". Поента свега јесте не заборавити и на сународнике који не говоре енглески, јер колико год се посао чинио лаким, до нивоа баналног, неко из сектора за заштиту од ризика то плаћа и цени.
Такође, српски се данас у великој мери удвара енглеском и наши говорници релативно лако прихватају енглески изговор производа: нрп. Fairy неће читати фаири или фаиру, већ фери; не заборавите на Мистер Мас'ла (Mr. Muscle), што се зваше Мистер Мусколо, чини ми се (увозник радио са Италијом).
Истина је да се овај модел ипак одлично продавао у Латинској Америци, али прича као таква је школски пример за часове маркетинга и именовање нових производа.
Посао провере имена бренда који се жели пласирати на одређено тржиште од лингвисте захтева управо то - да истражи да ли нека реч или име производа могу имати било какве негативне асоцијације на језику крајњег корисника.
Потребно је размислити о следећем:
- како реч изгледа на "папиру"
- како звучи или како може да звучи
Могући проблеми
Српски не познаје удвајање слова (осим у случају суперлатива где се "ј" може наћи поред другог "ј"). Ако име бренда садржи дупло слово, нпр. Gloopost, а клијент од вас тражи да му кажете како ће говорници матерњег језика (српског) изговорити име овог бренда, шта ћете му рећи?
Јасно је. Глупост. Али...
Да ли би и ваша баба ово изговорила тако? Можда, али тек у другом покушају јер би јој се учинило да личи на прво изговорено "глопост". Поента свега јесте не заборавити и на сународнике који не говоре енглески, јер колико год се посао чинио лаким, до нивоа баналног, неко из сектора за заштиту од ризика то плаћа и цени.
Такође, српски се данас у великој мери удвара енглеском и наши говорници релативно лако прихватају енглески изговор производа: нрп. Fairy неће читати фаири или фаиру, већ фери; не заборавите на Мистер Мас'ла (Mr. Muscle), што се зваше Мистер Мусколо, чини ми се (увозник радио са Италијом).
***Савршено средство за прање мозга.***
субота, 15. децембар 2012.
То је здраво!
Компанија SDL (коју вероватно сви знају по преводилачком софтверу из серије Традос), лансирала је бесплатну апликацију за машинско превођење - EasyTranslator, у десктоп варијанти (колекција пролеће/лето 2013.).

Иако резултати и нису баш најсјајнији, сам потез је за сваку похвалу. Временом ће се сигурно поправити и квалитет превода. Оно што је још важно јесте да апликација подржава и уживо ћаскање на различитим језицима и у различитим сервисима за ћаскање (gtalk, facebook messanger, итд).
То значи да ви можете да пишете на српском, а особа којој пишете да чита текст на енглеском, и обрнуто. Занимљиво је да је српски један од подржаних језика.
Када је реч о машинском преводиоцу порука, најбоља апликација коју сам до сада користио је Clownfish! Апликација се инкорпорира у Скајп и омогућава превод порука са високим процентом тачности (чини ми се да је око 90% онога о чему сам ћаскао са енглеским колегом било преведено тачно, а при том је звучало природно). Чак је и избор речи у преводу одговарао контексту!
Пробајте. Кад је џабе...

Иако резултати и нису баш најсјајнији, сам потез је за сваку похвалу. Временом ће се сигурно поправити и квалитет превода. Оно што је још важно јесте да апликација подржава и уживо ћаскање на различитим језицима и у различитим сервисима за ћаскање (gtalk, facebook messanger, итд).
То значи да ви можете да пишете на српском, а особа којој пишете да чита текст на енглеском, и обрнуто. Занимљиво је да је српски један од подржаних језика.
Када је реч о машинском преводиоцу порука, најбоља апликација коју сам до сада користио је Clownfish! Апликација се инкорпорира у Скајп и омогућава превод порука са високим процентом тачности (чини ми се да је око 90% онога о чему сам ћаскао са енглеским колегом било преведено тачно, а при том је звучало природно). Чак је и избор речи у преводу одговарао контексту!
Пробајте. Кад је џабе...
Нељудски ресурси
Здраво свима!
Желим укратко да вам најавим садржаје које ћете моћи да пратите на овом месту.
Коме је намењен овај блог?
Углавном пружаоцима и корисницима преводилачких, или у ширем смислу, лингвистичких услуга.
Шта ће бити теме?
- занимљивости и вести из бранше
- опис алата који вам могу помоћи у раду (софтвер)
- корисни линкови према другим сајтовима или блоговима на српском или на страном језику
- кратка упутства за коришћење одређених софтвера
- разно (чувена тачка "разно")
Пренесите вести свима за које мислите да им може користити. Посећујте овај блог често јер ћу га редовно ажурирати. Коментаришите. Двострана комуникација је од непроцењиве користи свима.
Желим укратко да вам најавим садржаје које ћете моћи да пратите на овом месту.
Коме је намењен овај блог?
Углавном пружаоцима и корисницима преводилачких, или у ширем смислу, лингвистичких услуга.
Шта ће бити теме?
- занимљивости и вести из бранше
- опис алата који вам могу помоћи у раду (софтвер)
- корисни линкови према другим сајтовима или блоговима на српском или на страном језику
- кратка упутства за коришћење одређених софтвера
- разно (чувена тачка "разно")
Пренесите вести свима за које мислите да им може користити. Посећујте овај блог често јер ћу га редовно ажурирати. Коментаришите. Двострана комуникација је од непроцењиве користи свима.
Пријавите се на:
Коментари (Atom)